Building a Real Service with Plumego: From HTTP Entry to Domain Logic
Introduction: Why “Real” Examples Matter
Many framework tutorials stop at the point where things become interesting.
They show:
- How to start a server
- How to define a route
- How to return JSON
What they rarely show is how a service behaves after six months of development, when:
- Business rules have multiplied
- Multiple engineers touch the same code
- Observability matters
- Refactoring becomes inevitable
This article is intentionally long and detailed. Its goal is not to demonstrate Plumego’s API surface, but to demonstrate how Plumego supports a real service architecture—one that is meant to evolve.
We will walk through a complete request lifecycle, from HTTP entry to domain logic and back, while continuously answering one question:
Why is this structured this way, and what problem does it solve later?
The Scenario: A User Management Service
To keep the discussion concrete, we will build a simplified but realistic User Management Service.
Functional Scope
The service will support:
- Creating users
- Fetching users by ID
- Basic authentication context
- Persistence via a repository abstraction
We will not focus on:
- UI concerns
- ORMs or specific databases
- Authentication protocols in depth
The focus is architecture and flow, not feature completeness.
Architectural Principles Before Code
Before writing any code, we establish a few non-negotiable principles. These principles are more important than any individual file.
Principle 1: Transport Is Not Business Logic
HTTP, JSON, headers, and status codes are transport concerns.
Business rules must not depend on them.
Principle 2: Domain Logic Is Framework-Agnostic
The domain layer should not import Plumego.
It should be testable without a server.
Principle 3: Explicit Boundaries Beat Convenience
Every boundary—transport, use case, domain, infrastructure—should be visible in code.
Plumego does not enforce these principles, but it rewards teams that adopt them.
High-Level Request Flow
Before diving into files, let us outline the flow of a single request:
- HTTP request arrives at the server
- Middleware chain executes
- Route matches and handler is invoked
- Handler parses input and delegates
- Use case orchestrates domain logic
- Domain entities enforce invariants
- Repository persists data
- Response is constructed and returned
Nothing here is novel. What matters is where each responsibility lives.
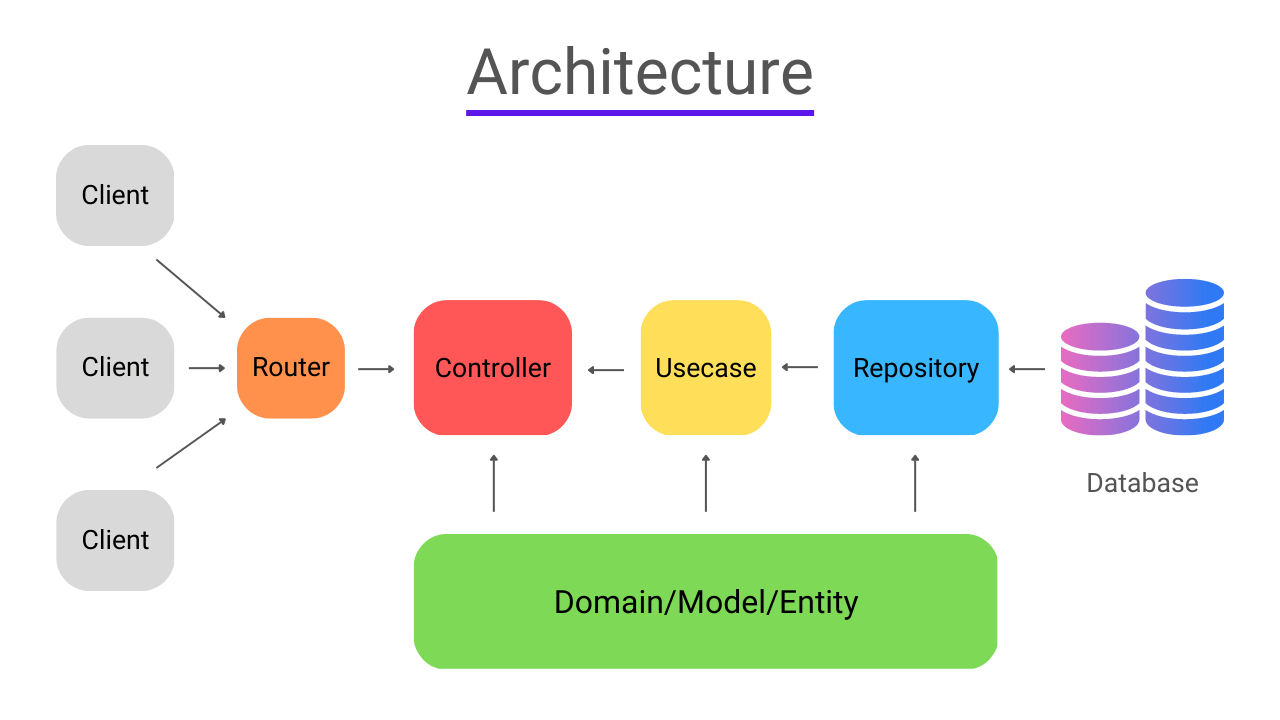
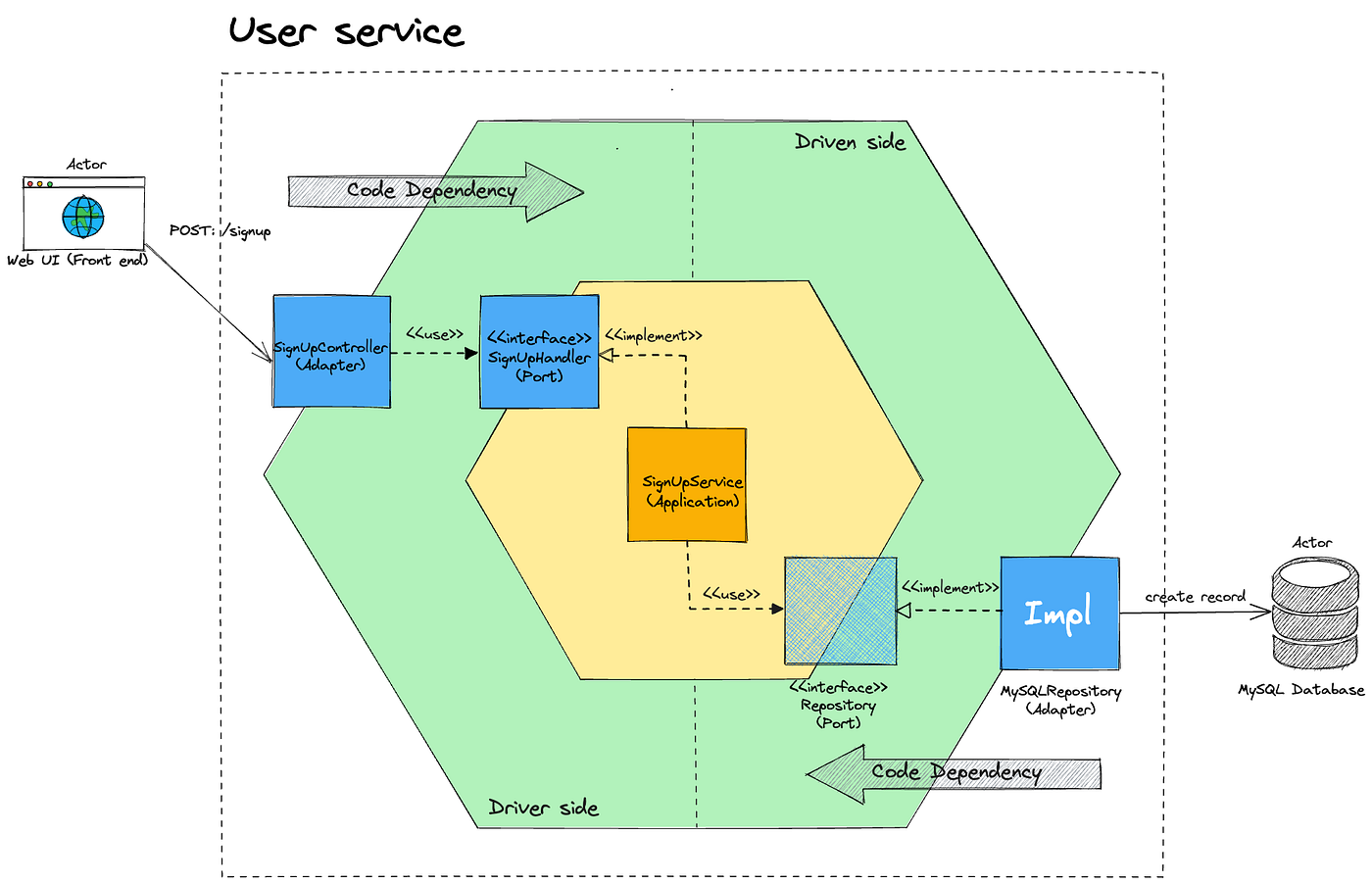
Project Structure: A Pragmatic Layout
Plumego does not dictate project structure, but certain layouts work especially well.
cmd/
server/
main.go
internal/
app/
application.go
wiring.go
transport/
http/
router.go
middleware.go
handlers/
user_handlers.go
usecase/
user/
create_user.go
get_user.go
domain/
user/
entity.go
errors.go
repository.go
infra/
repository/
user_repository_memory.go
pkg/
logging/
auth/
Why This Structure Scales
cmdowns process concernsappis the composition roottransportis replaceableusecaseexpresses intentdomainis pureinfracontains side effects
Plumego integrates cleanly because it stays at the transport and lifecycle boundary.
Step 1: Process Entry and Application Startup
main.go: Keep It Boring
func main() {
cfg := LoadConfig()
app := app.NewApplication(cfg)
if err := app.Run(); err != nil {
log.Fatal(err)
}
}
This file should answer only one question:
How does the process start and stop?
Anything more is a smell.
Step 2: Application as the Composition Root
The application layer wires everything together.
type Application struct {
server *plumego.Server
}
func NewApplication(cfg Config) *Application {
srv := plumego.NewServer(plumego.ServerConfig{
Addr: cfg.HTTPAddr,
})
registerMiddleware(srv)
registerRoutes(srv)
return &Application{server: srv}
}
Why This Matters
- Dependencies are visible
- No hidden global state
- Easy to test startup logic
- Clear lifecycle ownership
Frameworks that hide composition often create long-term rigidity.
Step 3: Middleware — The First Line of Reality
Middleware defines cross-cutting concerns. In Plumego, order is explicit and meaningful.
func registerMiddleware(srv *plumego.Server) {
srv.Use(recovery.Middleware())
srv.Use(requestid.Middleware())
srv.Use(logging.Middleware())
srv.Use(auth.Middleware())
}
Reading Middleware as Documentation
From this list alone, you can infer:
- Requests are recoverable
- Every request has an ID
- Logs are structured
- Authentication runs before handlers
This is architectural clarity through code.
Step 4: Routing as an Explicit Map
Routes are registered explicitly.
func registerRoutes(srv *plumego.Server) {
srv.Route(func(r *plumego.Router) {
api := r.Group("/api")
api.POST("/users", handlers.CreateUser)
api.GET("/users/:id", handlers.GetUser)
})
}
There is no scanning, no auto-binding, no inference.
You can answer “what endpoints exist?” by reading one file.
Step 5: Handlers as Thin Adapters
Handlers sit at the boundary between HTTP and application logic.
Create User Handler
func CreateUser(ctx *plumego.Context) error {
var req CreateUserRequest
if err := ctx.BindJSON(&req); err != nil {
return err
}
user, err := createUserUC.Execute(ctx.Context(), req.Email)
if err != nil {
return err
}
return ctx.JSON(201, user)
}
What the Handler Does Not Do
- It does not validate business rules
- It does not manage persistence
- It does not know database details
Handlers are intentionally boring.
Boring code is reliable code.
Step 6: Context as a Contract
Plumego’s context wraps context.Context but does not replace it.
Authentication Middleware Injects Context
func Middleware() plumego.Middleware {
return func(next plumego.HandlerFunc) plumego.HandlerFunc {
return func(ctx *plumego.Context) error {
userID := extractUserID(ctx.Request())
ctx.Set("user_id", userID)
return next(ctx)
}
}
}
Downstream Usage
userID, ok := ctx.Get("user_id")
In more advanced systems, this is wrapped in typed helpers.
The key point: context flow is explicit.
Step 7: Use Cases as Application Logic
Use cases orchestrate business actions.
type CreateUserUseCase struct {
repo user.Repository
}
func (uc *CreateUserUseCase) Execute(
ctx context.Context,
email string,
) (*user.User, error) {
u, err := user.New(email)
if err != nil {
return nil, err
}
return uc.repo.Save(ctx, u)
}
Why Use Cases Matter
- They encode intent
- They are framework-independent
- They are testable in isolation
- They form the backbone of business logic
Plumego encourages this separation by not providing a “controller-service-repository” abstraction.
Step 8: Domain Logic — Where Rules Live
User Entity
type User struct {
ID string
Email string
}
func New(email string) (*User, error) {
if !strings.Contains(email, "@") {
return nil, ErrInvalidEmail
}
return &User{
ID: generateID(),
Email: email,
}, nil
}
Domain Errors
var ErrInvalidEmail = errors.New("invalid email")
The domain:
- Has no HTTP knowledge
- Has no framework imports
- Enforces invariants centrally
This is the most important long-term payoff.
Step 9: Repository Abstraction
type Repository interface {
Save(ctx context.Context, u *User) (*User, error)
FindByID(ctx context.Context, id string) (*User, error)
}
The use case depends on the interface, not the implementation.
In-Memory Implementation
type MemoryRepository struct {
data map[string]*User
}
Plumego does not care what database you use.
That decision stays at the edge.
Step 10: Error Translation at the Boundary
Domain errors are not HTTP errors—until the boundary.
func ErrorMiddleware() plumego.Middleware {
return func(next plumego.HandlerFunc) plumego.HandlerFunc {
return func(ctx *plumego.Context) error {
err := next(ctx)
if err == nil {
return nil
}
switch err {
case user.ErrInvalidEmail:
return ctx.JSON(400, ErrorResponse{Message: err.Error()})
default:
return ctx.JSON(500, ErrorResponse{Message: "internal error"})
}
}
}
}
This keeps:
- Domain logic pure
- Transport logic localized
- Error behavior consistent
Step 11: Observability Emerges Naturally
Because the flow is explicit:
- Logs can attach request IDs
- Traces can wrap use cases
- Metrics can be added at boundaries
No hidden hooks are required.
Step 12: Graceful Shutdown and Lifecycle
Plumego exposes lifecycle control explicitly.
ctx, stop := signal.NotifyContext(context.Background(), os.Interrupt)
defer stop()
go app.Run()
<-ctx.Done()
app.Shutdown()
Production behavior is visible and controllable.
Why This Design Holds Up Over Time
After months of development:
- New engineers can follow the flow
- Refactors are localized
- Debugging starts with code, not guesswork
- Architecture remains readable
This is the cumulative benefit of explicit systems.
Common Anti-Patterns to Avoid
Even with Plumego, teams can sabotage themselves.
- Putting business logic in handlers
- Using context as a global variable
- Introducing reflection-heavy helpers
- Recreating “magic” abstractions
Plumego does not prevent these mistakes.
It simply makes them obvious.
Final Reflection: Plumego as an Enabler, Not a Crutch
This walkthrough shows that Plumego does very little—and that is its strength.
It does not:
- Decide your architecture
- Hide complexity
- Optimize for shortcuts
Instead, it provides:
- A clear runtime skeleton
- Explicit extension points
- Predictable behavior
If you value systems that remain understandable long after their initial authors are gone, this approach scales.
Real services do not fail because they lack features.
They fail because they lose clarity.
Plumego is built to protect that clarity, one explicit decision at a time.
Keep Reading
Follow the engineering thread
Get the next practical Birdor note, or browse the archive for related systems, tooling, and architecture work.